Fighting Misinformation: The Impact of Adversary Amplification in Society June 8, 2026
Posted by Chris Mark in cybersecurity, Industry News, Politics, privacy, security, Uncategorized, War.add a comment
This is a brief 10 minute discussion on Adversary Amplification. We all hear it every day. The outrage over AI DataCenters. The Lone Star Tick, name it. The people spreading this are not malicious, they are simply passionately misinformed and doing the work of a centralized agent. That could be China, Russia, or a competitor. With the advances in AI and explosion of Social Media, propagating and advancing these fears have become easy. Today’s hearings on the SPLC are a perfect example of Adversary Amplification. To think the SPLC is supporting NeoNazi groups, the KKK and other simply to hurt Republicans! Here is a link to the actual paper.
Statistical Anomalies in LA Mayoral Election: A Deeper Analysis June 7, 2026
Posted by Chris Mark in Industry News, Laws and Leglslation, News, Politics, Uncategorized.Tags: music, News, poetry, politics, writing
add a comment
DISCLAIMER: This article presents a statistical analysis of publicly available election data. It does not allege fraud, illegal conduct, or wrongdoing by any candidate, election official, or government entity. The statistical anomalies documented below demand transparent explanation. That is the appropriate standard in a functioning democracy. Nothing more is claimed here.
Introduction
Elections in the United States are decided by votes. The integrity of those votes depends not only on the honesty of those casting them but on the transparency and consistency of how they are counted. When the statistical profile of mail-in ballot counting diverges from election day results by a margin that falls outside any reasonable probability model, the public interest demands a clear and documented explanation.
This article presents a statistical analysis of Spencer Pratt’s performance in the 2026 Los Angeles mayoral primary election. The analysis compares his election day vote share to his performance in subsequently counted mail-in ballot batches. The divergence between these two data sets is not a matter of opinion or political interpretation. It is a mathematical fact that warrants examination.
This is not an endorsement of any candidate. It is an application of basic statistical principles to publicly available election data.
Background: The Race
The 2026 Los Angeles mayoral primary featured fourteen candidates, with incumbent Mayor Karen Bass seeking a second term against a field that included former reality television personality Spencer Pratt, a registered Republican whose Palisades home was destroyed in the devastating 2025 wildfires, and Los Angeles City Councilwoman Nithya Raman, a Democratic Socialists of America member challenging Bass from the left. [1]
Under California’s election rules, if no candidate receives more than fifty percent of votes in the primary, the top two candidates advance to a November runoff election. Mayor Bass secured enough votes to advance. The race for second place — and the November runoff slot — became a contest between Pratt and Raman. [2]
A pre-election UC Berkeley-LA Times poll conducted in May 2026 showed Bass with twenty-six percent support, Raman at twenty-five percent, and Pratt at twenty-two percent among likely voters — a margin of error of approximately three percent. [3]
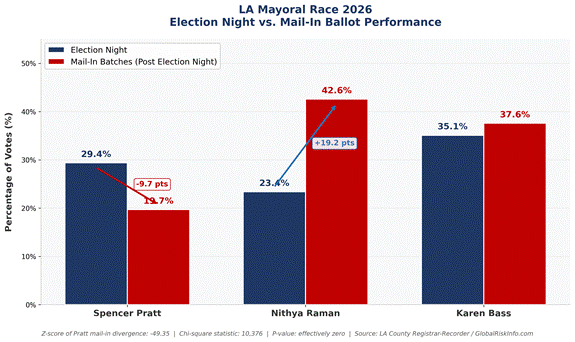
Figure 1: Election Night vs. Mail-In Ballot Performance — LA Mayoral Race 2026
Election Night Results
Pratt significantly outperformed his pre-election polling. With sixty-six percent of the expected vote counted on election night, results showed:
Karen Bass: 35% Projected to advance to November runoff
Spencer Pratt: 29.4% Comfortably in second place
Nithya Raman: 23.4% Trailing Pratt by approximately six percentage points
Pratt held what appeared to be a comfortable lead over Raman. By Thursday, with additional votes counted, the gap remained near six percentage points. [4]
With 163,549 votes in Los Angeles’ latest tabulation, Pratt maintains a near 6% lead on Raman, who has 130,473 votes. — Fox News, Thursday June 5, 2026 [4]
The Mail-In Ballot Divergence
As mail-in ballot batches were counted and released in the days following the election, a striking divergence from election night results emerged. Rather than tracking the established proportions, the mail-in batches showed a dramatic and statistically extraordinary shift.
The Zero-Vote Batch
The initial anomaly identified was a batch of approximately 24,000 mail-in ballots in which Pratt received zero votes. At his election night rate of 29.4 percent, the expected number of Pratt votes in such a batch would be approximately 7,056.
Probability of zero Pratt votes in 24,000 ballots at 29.4%: 1 in 10^3,629 Effectively impossible by random chance
For context: the total number of atoms in the observable universe is estimated at approximately 10^80. The probability of Pratt receiving zero votes in that batch, if his actual support rate was 29.4 percent, is incomparably smaller than randomly selecting one specific atom from the entire universe on the first attempt.
The Subsequent Batch Analysis
Examining the larger batch of mail-in votes reported since Thursday — totaling 54,245 votes across Pratt, Raman, and Bass — the divergence becomes statistically quantifiable. [5]
Pratt mail-in share: 19.7% vs. 29.4% election night — deficit of 9.7 percentage points
Raman mail-in share: 42.6% vs. 23.4% election night — gain of 19.2 percentage points
Pratt vote deficit: 5,237 votes Below statistically expected count in this batch alone
In concrete terms: if mail-in ballots had simply reflected election night proportions, Pratt would have received approximately 15,948 votes in the analyzed batch. He received 10,711 — a shortfall of 5,237 votes in a single counting batch.
Statistical Analysis
The Chi-Square Test
The chi-square test measures whether an observed distribution of votes differs significantly from what would be expected based on a reference distribution — in this case, election night proportions. Applying this test to the mail-in batch:
Chi-square statistic: 10,376.18 Extraordinarily high — any value above 6 is statistically significant at the 95% confidence level
Degrees of freedom: 2 Three candidates minus one
P-value: Effectively zero The probability this divergence occurred by random chance
A p-value of zero means the observed distribution of mail-in votes cannot be explained by random sampling variation from the election night population. Under standard statistical thresholds, a p-value below 0.05 is considered statistically significant. A p-value below 0.001 is considered highly significant. This result is not in that range — it is below any threshold that statistical science has developed to describe.
The Z-Score Analysis
The z-score measures how many standard deviations an observed result falls from its expected value. In normal human affairs, results beyond three standard deviations are considered extraordinary and warrant investigation. Results beyond five standard deviations are considered essentially impossible by random chance.
Z-score for Pratt’s mail-in performance: -49.35 Forty-nine standard deviations below his election night rate
A z-score of negative forty-nine does not exist in the normal range of human statistical experience. To find a naturally occurring phenomenon with a z-score of this magnitude would require examining astronomical datasets, not election results. This number is not an anomaly. It is a mathematical impossibility under any standard probability model that assumes mail-in voters come from the same population as election day voters.
In statistics, anything beyond three standard deviations is considered extraordinary. Forty-nine standard deviations is not a number that occurs in nature through random variation.
The Current State of the Race
The cumulative effect of these mail-in batches has been dramatic. [6][7]
Pratt current share (78% counted): 27.3% Down from 29.4% election night
Raman current share (78% counted): 26.2% Up from 23.4% election night
Current Pratt lead: Approximately 7,500 votes Narrowing with each batch
Raman received forty percent of votes counted on Saturday — a figure that, if sustained, would be sufficient to overtake Pratt before all ballots are counted. [7]
The race remains uncalled. California law allows counties up to thirty days to complete the official canvass. Millions of mail-in and provisional ballots remain to be processed in Los Angeles County alone — the largest voting jurisdiction in the United States, with 5.8 million registered voters. [8]
Three Possible Explanations
Statistical analysis identifies the anomaly. It does not, by itself, determine the cause. There are three explanations that must be considered:
Explanation One: Population Differences
California leads the nation in mail-in voting, with eighty-one percent of voters sending their choices by post in 2024 — nearly double the national average. [9] It is theoretically possible that Pratt’s support is concentrated among voters who specifically chose to vote in person on election day, and that mail-in voters skew heavily toward Raman and Bass.
However: even accepting significant population differences, a forty-nine standard deviation divergence cannot be explained by population variation alone. The pre-election poll showing Pratt at twenty-two percent among likely voters — not a dramatically different figure from his election night performance — did not distinguish between mail-in and in-person likely voters in a manner that would predict a divergence of this magnitude.
Explanation Two: Counting Methodology or Batch Composition
It is possible that specific batches of mail-in ballots being counted represent geographically concentrated areas where Raman has disproportionate support — council districts she represents, for example — and that the batches are not representative of the overall mail-in population.
If this is the explanation, the Los Angeles County Registrar-Recorder should be able to document precisely which geographic areas each batch represents and demonstrate that the composition explains the divergence. That documentation should be made public.
Explanation Three: Something Requiring Investigation
The third possibility is that something in the counting or reporting process is producing results that do not accurately reflect the votes cast. This article does not allege this is the case. However, the statistical evidence is sufficiently extreme that it cannot be dismissed without documented, transparent explanation of the first or second type.
What Transparency Requires
In a functioning democracy, election results that produce statistical anomalies of this magnitude demand documented explanation — not reassurance, not dismissal, but transparent accounting of the counting process. Specifically:
The Los Angeles County Registrar-Recorder should publicly document the geographic composition of each mail-in batch released since election day — demonstrating which precincts or council districts each batch represents and how that composition accounts for the observed divergence.
The methodology for selecting, processing, and releasing mail-in ballot batches should be made publicly available.
Any candidate or party requesting observation of the counting process should be granted that access consistent with California election law.
The zero-vote batch — 24,000 ballots producing zero votes for a candidate receiving approximately 29.4 percent of all other votes — requires specific and documented explanation.
The appropriate response to a statistical anomaly in a democracy is transparency and documentation — not political dismissal or reassurance. The numbers are what they are. They deserve a clear answer.
Conclusion
Spencer Pratt received approximately 29.4 percent of votes cast on election day in the Los Angeles mayoral primary. In subsequently counted mail-in ballot batches, he has received approximately 19.7 percent — a divergence of 9.7 percentage points that produces a z-score of negative forty-nine and a chi-square statistic of over 10,000.
These numbers are not consistent with random sampling variation from the same voter population. They are not explained by normal statistical fluctuation. They demand a documented, transparent, and geographically specific explanation from Los Angeles County election officials.
The question is not whether Spencer Pratt should be the next mayor of Los Angeles. The question is whether the vote count accurately reflects the votes that were cast. In a democracy, that question is never inappropriate to ask — and it is always appropriate to demand a clear answer.
Chris Mark is an Enterprise Security and Risk Strategist, published author, co-author of PCI DSS, named patent holder, and United States Marine Corps combat veteran. He writes on security, risk, and emerging threats at GlobalRiskInfo.com.
References
[1] NBC News. (2026, June 2). Los Angeles Mayor Primary 2026 Live Results. nbcnews.com/politics/2026-primary-elections/los-angeles-mayor-results
[2] ABC7 Los Angeles. (2026, June 4). Los Angeles mayor race: Live election results and updates on front runners Karen Bass, Nithya Raman, Spencer Pratt. abc7.com
[3] CBS Los Angeles. (2026, June 7). Pratt’s lead over Raman slims in new L.A. mayoral election results. [Citing UC Berkeley-LA Times poll, May 28, 2026, margin of error approximately 3%.] cbsnews.com/losangeles
[4] Fox News. (2026, June 5). Spencer Pratt loses ground to Democrat while Hilton maintains lead in latest California ballot batch drop. foxnews.com
[5] Fox 11 Los Angeles. (2026, June 6). LA mayor’s race: Nithya Raman surges, closes gap on Spencer Pratt for runoff spot. foxla.com. [Reporting Raman: 23,115 votes (38%), Bass: 20,419 votes (34%), Pratt: 10,711 votes (18%) in mail-in batch since Thursday.]
[6] CBS Los Angeles. (2026, June 7). Pratt’s lead over Raman slims in new L.A. mayoral election results. cbsnews.com/losangeles. [Citing 78% of votes counted, Pratt 27.3%, Raman 26.2%.]
[7] The Wrap. (2026, June 7). Nithya Raman Inches Within 1% of Spencer Pratt After Winning 40% of Saturday Tally in LA Mayor’s Race. thewrap.com
[8] NBC Los Angeles. (2026, June 6). Gap between Pratt and Raman gets tighter in LA mayoral race. nbclosangeles.com. [Noting 5.8 million registered voters in Los Angeles County.]
[9] Fox News. (2026, June 5). Spencer Pratt loses ground to Democrat. [Citing California leads nation in mail-in voting at 81% of voters in 2024, nearly double national average of 43%.]
[10] Statistical methodology: Binomial probability calculation P(X=0) = (1-p)^n. Chi-square test comparing observed mail-in distribution to election night baseline. Z-test for proportions: z = (p_observed – p_expected) / sqrt(p_expected*(1-p_expected)/n). All calculations performed using Python scipy.stats library.© 2026 Chris Mark / GlobalRiskInfo.com. All rights reserved. Reproduction with attribution
MY LATEST BOOK RELEASED! “The Science of Security” May 16, 2026
Posted by Chris Mark in cyberespionage, cybersecurity, Industry News, InfoSec & Privacy, Laws and Leglslation, Piracy & Maritime Security, Risk & Risk Management, security, security theater.Tags: ai, artificial-intelligence, cybersecurity, data breach, History, InfoSec, Maritime Security, philosophy, Piracy & Maritime Security, risk management, security, technology
add a comment
Announcing Scientia Securitatis: The Science of Security

After 34 years across nearly every security domain that exists — armed physical security at an overseas critical installation, combat force protection, security in a regional hospital’s psychiatric ward, payment-card industry compliance, armed maritime contracting off the East African coast, and a return to enterprise cybersecurity that has occupied the past decade — I have written the book I wish someone had written when I started.
Scientia Securitatis: The Science of Security — Theory, Frameworks, and Practice is available now.
The gap this book is intended to fill
The security profession does not lack books. Walk into any bookstore, scan any conference vendor floor, search any retailer’s security category, and you will find more material on cybersecurity, physical security, risk management, military theory, criminology, intelligence analysis, and organizational resilience than any single practitioner could read in a career. The field is overwhelmed with information.
What it lacks is integration.
Each security domain has developed its own vocabulary, its own frameworks, its own bestsellers, its own consultants. Each domain — when traced carefully to its analytical roots — is reaching for the same underlying concepts the next domain over named differently. Practitioners in physical and cybersecurity are working on the same analytical problems and rarely speak to one another. When they do, they discover that they have been duplicating each other’s work for decades.
Scientia Securitatis is an attempt to make that recognition the starting point of professional practice rather than an accident a few practitioners stumble into late in their careers.
What’s in the book
The book runs to 525 pages across 11 chapters and three appendices. It develops four original analytical frameworks:
- The Mark Heptad — a taxonomy of seven adversary motivations (financial, espionage, war/defense, facilitation, hacktivism, revenge, nuisance) that maps directly to deterrence strategy
- The IMCM Framework — Ignorance, Mistake, Complacency, Malice — for classifying human-induced vulnerabilities and matching them to specific interventions
- The DIVE Framework — Direction, Intensity, Vulnerability, Exposure — for assessing specific exposure surfaces
- The Multiplicative Security Model — the mathematical basis for defense-in-depth, with implications for how security architecture should actually combine
These original frameworks sit within a broader analytical apparatus drawn from criminology (Cohen and Felson’s Routine Activity Theory, Cornish and Clarke’s Twenty-Five Techniques of Situational Crime Prevention), cognitive science (Kahneman and Tversky on judgment under uncertainty), military theory (Sun Tzu, Clausewitz, contemporary unrestricted warfare doctrine), and systems-safety scholarship (James Reason’s Swiss Cheese Model, Charles Perrow’s normal-accident theory).
The book also examines — and critically engages — the victim-blaming reflex that dominates post-incident analysis, drawing on the foundational criminological literature on victim precipitation and contemporary case studies including Equifax, OPM, Target, and Snowflake.
A note on the Latin title
Scientia Securitatis translates as “the science of security,” and the choice was deliberate. The Latin signals that the book engages security as a serious analytical discipline whose intellectual roots long predate the cybersecurity industry’s tendency to treat its problems as historically unprecedented. The phenomena security examines are ancient; the framework for studying them rigorously has been available since at least the mid-20th century. The book argues that practitioners have, with rare exceptions, declined to use it.
Who this book is for
This book is for the practitioner who has noticed that decades of escalating security investment have not produced proportional security gains, and who wants to understand why. It is for the security executive building defensible programs across multiple domains. The policy professional confronting unrestricted warfare doctrine. The risk and compliance leader who suspects that frameworks alone are not stopping sophisticated adversaries. The graduate student approaching security as an analytical discipline rather than a job category.
It is not a tactical handbook. It is not a configuration guide. It is the analytical apparatus that determines whether tactical choices are well-made — the apparatus the field has been operating without.
Where to get it
Scientia Securitatis: The Science of Security is available now on Amazon in eBook, paperback, and hardcover formats:
If you find the book useful, please consider leaving a review. Self-published analytical nonfiction lives and dies by word-of-mouth among the practitioners it was written for — and a thoughtful Amazon review from a working professional is worth more to other professionals than any amount of marketing.
— Chris Mark
What Coronavirus can Teach us about CyberSecurity February 28, 2020
Posted by Chris Mark in cybersecurity, Data Breach, Industry News, InfoSec & Privacy.Tags: adaptation, Chris Mark, coronavirus, data breach, disease x, johari, risk, RSA, security, threat, virus
add a comment
 The 2020 RSA CyberSecurity Conference was held recently in San Francisco, California. There were some notable companies that elected to not attend this over safety concerns related to Coronavirus. On February 25th the mayor of San Francisco declared a state of emergency for their city over Coronavirus fears.
The 2020 RSA CyberSecurity Conference was held recently in San Francisco, California. There were some notable companies that elected to not attend this over safety concerns related to Coronavirus. On February 25th the mayor of San Francisco declared a state of emergency for their city over Coronavirus fears.
This state of emergency was declared is in spite of the fact that there are no confirmed cases of Coronavirus in the city. Mayor Breed, in discussing her prudent steps stated: “We see the virus spreading in new parts of the world every day, and we are taking the necessary steps to protect San Franciscans from harm…”
First identified in Wuhan, China in late 2019, Coronavirus (covid-19) has reportedly infected over 80,000 people worldwide and has resulted in over 2,700 deaths on several continents. Recently, the World Health Organization identified the newly identified Coronovirus as a potential “Disease X”. “Disease X” was added to World Health Organization’s “Prioritizing diseases for research and development in emergency contexts” list of illnesses. This list includes such diseases as the Crimean-Congo hemorrhagic fever (CCHF), Ebola and Marburg virus disease, Lassa Fever, MERS, SARS, Nipah and henipaviral diseases, Rift Valley fever and Zika. Importantly, “Disease X”:
(…represents the knowledge that a serious international epidemic could be caused by a pathogen currently unknown to cause human disease, and so the R&D Blueprint explicitly seeks to enable cross-cutting R&D preparedness that is also relevant for an unknown “Disease X” as far as possible) (emphasis added).
What can the current Coronavirus situation teach us about cybersecurity?
Reflecting upon the situation in San Francisco and the WHO’s statements, it is possible to utilize the Johari Window to analyze the situation. The Johari Window[1]developed by psychologists Joseph Lutz and Harrington Ingram in 1955 and reintroduced to the American Public in 2012 when then Secretary of State in referencing Iraqi Weapons of Mass Destruction stated:
“…there are known knowns; there are things we know we know. We also know there are known unknowns; that is to say we know there are some things we do not know. But there are also unknown unknowns—the ones we don’t know we don’t know…it is the latter category that tend to be the difficult ones.” (paraphrased)
The Johari Window identifies four panes of knowledge. They include: The “known/knowns” where both the person and others know of a given situation. There is the “Known/Unknown” where the person knows and others do not know of a situation. Consider a personal secret that has not been shared with others. There is then an “Unknown/Known” where the situation is not known the person yet is known to others. In simple terms think of a surprise birthday party where everyone but the birthday boy/girl is aware. Finally, there are “unknown/unknowns” where neither the party knows. This is the truest example of an ‘unknown’ and represents, the most difficult situation to analyze because it truly represents a position of ignorance on both parties.

In 2016 the World Health Organization identified that there was a conceptual, although yet undefined threat that was both unknown to others and to themselves but they understood that, theoretically, existed and would present a major risk if and when it was eventually realized. This, they proactively identified as ‘Disease X’. This was the ‘unknown/unknown’ in the Johari Window until the time that it was identified as Coronavirus.
It is now a ‘known/known’ threat although countries are still struggling to identify how to deal with the risk it presents. Until it was actually realized, however, there was little any country could do except wait until it was realized. Once it was identified, then actual defensive and protective measures could be put into place to address the threat.
In much the same way, organizations dealing with cybersecurity today are presented with the ‘unknown/unknown’ of the conceptual “Disease X” threat in cybersecurity. This is any yet unidentified and yet predicted threat that may impact their organization in the not too distant future. Companies are faced with attempting to develop security and continuity plans for a threat that they do not yet know exists and what specifically that threat encompasses. On a nearly daily basis, however, a ‘Disease X’ arises in cybersecurity and companies are forced to react quickly and decisively to address such threats. Adding to the threat is the fact that these threats are not naturally occurring and are, in fact, created by humans – intent on creating harm.
Compounding the problem of the ‘unknown/unknown’ is the idea of threat adaptation in known threats. While not modified by naturally security processes, security strategies, like those of disease control must also deal with threat adaptation. Using the Coronavirus as an example, according to a South China Morning Post article posted on February 4th, 2020 Chinese scientists had already:
“…detected “striking” mutations in a new coronavirus that may have occurred during transmission between family members.” It further states that: “While the effects of the mutations on the virus are not known, they do have the potential to alter the way the virus behaves.”
It has been well established that Influenza virus ‘shift’ and ‘drift’ antigenically. Without delving into the specifics of how these occur, according to the Center for Disease Control and Prevention, states that:
“When antigenic drift occurs, the body’s immune system may not recognize and prevent sickness caused by the newer influenza viruses. As a result, a person becomes susceptible to flu infection again, as antigenic drift has changed the virus enough that a person’s existing antibodies won’t recognize and neutralize the newer influenza viruses.”
While not a direct corollary to a natural viral drift or shift, human actors respond in a similar way when attempting to commit criminal acts. They ‘adapt’ to the changing security environment and are defined as ‘adaptive threats’. According to the Department of Homeland Security’s Security Lexicon, Adaptive Threats are defined as:
“…threats intentionally caused by humans.” It further states that Adaptive Threats are: “…caused by people that can change their behavior or characteristics in reaction to prevention, protection, response, and recovery measures taken.”
In short, as defenses improve, threat actors change their tactics, and techniques to adapt to the changing controls and prevent the established controls from identifying and protecting against the newly adapted threat. As the threat actor improves their capabilities the defensive actors necessarily have to change their own protections. This cycle continues ad infinitum until there is a disruption. This recurring cycle is known as the Defense Cycle.
Consider medieval castles. Originally, they were built of wood. Those assaulting castles would simply use fire to burn the castles to the ground. Castle makers then built Castles of stone. Assaulters then created siege engines to knock down the walls or began digging under the walls to ‘undermine’ them. Castle walls were made larger and stronger and were nearly impenetrable until cannons were introduced. Even in situations where the attackers could not ‘storm the castle’ they would simply lay siege and starve the inhabitants until they capitulated. This is a classic example of threat adaptation and the defense cycle.
In a more relevant and timely example consider a standard network with security controls applied commensurate with the identified risks. An attacker may try an attack against the network layer. If this is ineffective and the incentive is great enough the attacker will likely modify their behavior and attack methodology to attempt to circumvent some other control. This process continues until a resource has been compromised.
Applying the concepts addressed in this article, a newly identified or developed exploit is the proverbial “Disease X”. As it has not yet been identified, the organization has no definitive defense against it. Once it is identified and known, then the company can begin identifying new controls to address the newly identified risk. The attacker will then, once again, modify their behavior. As stated, this cycle can continue ad infinitum.
In 2020, organizations are dealing with myriad threats. First there are the ‘unknown/unknowns” that represent the “Disease X”of the cyber attack world. These may include new attack vectors, or zero day exploits. Secondly, organizations are faced with defending against motivated, determined adversaries who are not only is focused on attacking networks and resources but are continually adapting their strategies as defenses improve. While not a direct correlation, by looking at nature and how diseases impact our society, organizations can better understand their own security strategy and risk management practices.
1,000,000 InfoSec Job Openings in 2016! May 10, 2016
Posted by Chris Mark in cybersecurity, Industry News, InfoSec & Privacy.Tags: assurance, Breach, careers, Chris Mark, hack, information, job market, PCI, security
add a comment
 A recent article in Forbes Magazine outlines the current and projected information security job market. According to the article the current job market is valued at $75 billion and is expected to grow to $170 Billion by 220. More profoundly, CISCO estimates that there are currently 1 million InfoSec job openings in the US with, according to Peninsula Press, 209,000 currently unfilled! According to Virginia Lehmkuhl-Dakhwe, director of the Jay Pinson STEM Education Center at San Jose State University “The number of jobs in information security is going to grow tenfold in the next 10 years,”
A recent article in Forbes Magazine outlines the current and projected information security job market. According to the article the current job market is valued at $75 billion and is expected to grow to $170 Billion by 220. More profoundly, CISCO estimates that there are currently 1 million InfoSec job openings in the US with, according to Peninsula Press, 209,000 currently unfilled! According to Virginia Lehmkuhl-Dakhwe, director of the Jay Pinson STEM Education Center at San Jose State University “The number of jobs in information security is going to grow tenfold in the next 10 years,”
I have been fortunate to have had a great career in information security over the past 15 years. While my experience is unique, I have had opportunity to travel the World and work with some of the largest, and most complex companies around. I have spoken at scores of events and have published dozens of articles and white papers.
Last year I wrote a blog post about how to get into the InfoSec career field. Two things that many people may want to know off the bat. 1) a College Degree is NOT required (although often very helpful) and 2) The pay is VERY good. (basic supply and demand). In my experience most people could probably get into the field with anywhere from 9-18 months of self-study. You can get in quicker if you attend course. For more information, please read my blog post: Getting Info Information Assurance Careers.

